I hope you two don’t mind my intrusion, but I’d like to chime in a few points, even if I’m a bit late to some of it.
Two things doing the same thing is probably more common than you think. Can you imagine having to write x += ~0 instead of x-- because the decrement operators are technically redundant for literals?
As @pharap said, programming in anything higher-level than assembly is all about abstractions for expressing intent. If you use a struct, you’re defining a data structure. This is very different from classes which are about responsibilities, not data per se. Even if they’re the same thing to the compiler, using one thing when you should be using the other is just as weird as using an addition to subtract.
Emacs is obviously superior!
The initial effort is probably the main drawback to Linux and Vi/Emacs. To make a parallel with programming languages: IDEs, Windows/MacOS are to Basic like Vi/Emacs/Linux are to C++. At first you don’t see the point and think “Why would anyone use this?” After a few weeks of breaking old habits and developing new ones, going back feels really limiting.
Using the keyboard instead of the mouse in the IDE is like switching from a gamepad to mouse+keyboard in FPS games. Sure, you can use a gamepad to aim, walk and shoot… but it’s really clumsy in comparison.
Sorry, that argument was really dumb from me, I worded it very wrong, I agree of course.
What I meant was more of a: there are two ways to do it - neither is right or wrong - but the mixture, the emerging inconsistency and blurred border between the two are wrong. No such problems emerge when you mix x++ with ++x. It’s kind of like metric vs imperial units - actually not a good example either, because here you can simply decide for one of these units. You can probably come up with rules to prevent the inconsistencies, such as when it has a member function, it has to be a class, otherwise it has to be a struct… or something like that - but that should be the language’s responsibility to define.
You know, people often think the more options the better, right? Actually no, clarity is especially important with abstractions.
The fact that @Pharap thinks of the two as basically the same (which they are) and you see a fundamental difference (which there is) confirms there is a confusion. You need to set up extra policies to deal with this. It’s an extra friction, as Jonathan Blow says (I think he bashes C++ too).
Anyway…
Emacs is obviously superior!
It has to already be clear I go with vim
Using the keyboard instead of the mouse in the IDE is like switching from a gamepad to mouse+keyboard
+1
Have you actually never really used it for anything or just not in a serious way? Try dual boot for start.
A running joke is that Emacs is an operating system. So you can just decide to install Emacs as an abstraction layer and be free of any underlying OS
Same thing, different words. To the compiler, structs and classes are the same thing, to the programmer they convey meaning. What that meaning actually is isn’t part of the C++ language. The language has latitude for you to have a “dialect” or “accent” (drawing a parallel with spoken languages): a way of expressing ideas that makes the most sense to your specific situation/team. This is intentionally subjective. If we were only concerned about what has meaning to the compiler, we wouldn’t use variable names, just A, B, C, D…
In a talk Bjarne Stroustroup complained about people who try to define what C++ code should look like. Instead, he purposely avoids doing so, since what makes sense in his shoes might not make sense in others’. His goal was that the language should facilitate a diverse set of styles.
To use your wording, C++ doesn’t have blurred borders. It aims to have no borders. You set the borders that make sense to your particular situation.
I started using Emacs because of this. I have to edit files on Linux, Windows, occasionally MacOS, and in a terminal over SSH. I got tired of switching IDEs every time I had to switch to a different environment/language. XCode was the final straw. The only only editors that I could expect to use for everything/everywhere were Vim and Emacs. I spent a week on each to see what “stuck”.
Emacs won for me, though I consider it and Vim equivalent.
You can. I tried it. I didn’t get on with it so I went back to paint.
I partly agree with some of the Unix philosophy.
For one thing I regularly write ‘throwaway’ programs, usually to calculate something for me or process some data or sometimes as a proof of concept.
I like the idea of making pipable programs, but the problem is that the idea that ‘text streams are a universal interface’ doesn’t always hold true in the real world.
Those text streams have to have conventions about what they contain, and they don’t always contain the same information, so you end up needing to transform it or filter it.
I don’t know if I type faster than I speak or speak faster than I type,
but I know that I think faster than I speak or type because I’m usually thinking several words ahead of what I’m typing and often have to slow down to stop myself skipping words or making mistakes.
I’d say that’s possibly less of an issue with code than with words/speech though.
I admit I find typing easier than speaking though.
I often type text walls but ironically I’m quite a quiet person.
Also most people think in terms of symbols and diagrams as well as words and text, and those are hard to convey with just typing.
A state diagram is usually a better expression of a state system than some code implementing a state system, which is one of the reasons why documentation is so important.
I used to play TF2 with a touch-pad.
That said, even if I still had a usable laptop I rarely travel far and I’ve never attempted to work while in motion, so I can’t really say either way.
Though I think one of the modern touch-screen laptops would make that a darn sight easier.
(You’d probably struggle to find the room to use a laptop on most British trains anyway.)
I’ve suddenly realised the irony of those people only wanting keyboards when there are lots of the people who like using tablets, which are pretty much all mouse and very little keyboard.
Like I say, I’m not usually in a hurry to type my code.
Though even then I usually find it’s quicker to grab the mouse and click where I want the cursor to go than to keep tapping or holding the arrow keys.
Also I’ll usually flick to a different process at some point (web browser, file browser, steam, music player etc) anyway, or remove one hand so I can have a sip of my drink.
I find that I don’t always need to see what I’m typing to know what I’m typing.
Sometimes I stare at my hands on the keyboard rather than the screen.
Sometimes I just have my eyes closed or looking elsewhere.
I have no comfort issues using a mouse. I find my mouse just as comfortable as a keyboard as long as I’m not using it for hours at a time.
It still is :P
Not at all.
Even certain variations of assembly have abstractions.
Some kinds of assembly have aliases (e.g. LSH x for ADD x, x) or some kind of pre-increment/post-decrement syntax for alternate versions of instructions (e.g. the MOS6502 and its different addressing modes).
Yup, x - y == x + -y.
In fairness, if you’re thinking in terms of group theory then the addition of an additive inverse isn’t all that weird,
but most programmers aren’t thinking in terms of group theory when writing programs :P
I see the point for some people who really do have a lot of things they want to pipe and automate and the like, but for me I think that would be a bit of a waste.
I can’t even begin to think what I’d possibly do with it.
I do actually use my %PATH% on Windows and I have got things like GHC and git set to be usable from the command line, but I find that I rarely use them.
In the case of git I use the GitHub UI far more often, even though I know there are certain things that are harder to do with the UI (like undoing the last commit to master when it’s tragically incorrect :P).
Even if only using the mouse and not using the keyboard sped up my programming process considerably,
I don’t think the saved time would make me more productive.
(If anything I’d just spend that time procrastinating more. :P)
Also part of using the mouse is a matter of comfort/laziness.
I know that I can use Alt+1,2,3 etc to switch tabs in some of my editors, but it feels more clumbsy to me than using the mouse, and I have to spend mental effort figuring out the number of the tab I want instead of lazily pointing at it.
What sort of inconsistency?
To use these as an example:
++x increments x and the result of the expression is the incremented value of x x++ creates a termporary variable (let’s call it x2), increments x and the result of the expression is x2.
Otherwise they’re exactly the same, if you treat them both as a statement rather than an expression then they both have the effect of incrementing x, and which one you choose to use is a matter of preference.
I opt to use ++x in every case where I could use either, whereas a lot of other people opt to use x++ when they could use either.
There’s actually less of a consensus on this than when to use class/struct.
struct creates a product type, but all members are public by default. class creates a product type, but all member are private by default.
If you use explicit access modifers all the time then they both have the same effect of declaring a product type, and which one you choose to use is a matter of preference.
So it’s essentially the same conundrum, but with a more common consensus of ‘use struct for traits and plain-old-data types, use class for more complex types’.
You can choose to stick to just using class or just using struct.
I believe most of my code uses class almost all of the time.
The only time I purposely opt for struct is when creating traits-like classes or metatemplate utilities.
I beg to differ.
The Go programming language has decided to try to end the brace war by forcing people into using a certain brace style rather than allowing programmers to use the brace style that suits them.
The language is worse because of it.
Sometimes it’s better to just let the programmer choose rather than forcing them to do something a single way.
That’s one of the reasons Perl’s mantra is “there’s more than one way to do it”.
True, but whether the type says class or struct at the start has so little bearing on what comes next that it’s usually negligable.
It’s like opting for auto n = 5 over int n = 5.
In terms of the language they are technically the same apart from the default access modifer which is fundamentally different.
How people choose to use them is a much bigger difference.
People have their own conventions for what extra meaning gets assigned to them, and like I said earlier the convention is usually ’struct for C-style bags of data, class for proper classes’.
It’s as much of a convention as opting to avoid this-> for accessing members or naming members with an m_ prefix.
I’ve tried it briefly on other people’s laptops and I’ve seen several variants in action.
Nothing has really gripped my interest enough to think of it as anything more than “something I’ll give a try someday”.
Too much hassle.
Partitioning the harddrive, installing, finding software to put on it, getting used to the new software etc.
All that stuff takes time, and I can’t really see what benefit it would give me.
Like I said earlier, if it made my day-to-day process more efficient then I’d just end up wasting the saved time.
I’m not aiming to be more efficient.
If I wanted to be more efficient and to produce more code, I’d start by spending less time on forums, which by far eats more of my time than time spent using a mouse. :P
I suddenly remembered:
although a lot of people are used to using these terms because that’s what they’re called in a lot of common media,
these are both outdated/incorrect.
I see your points on classes vs structs - I don’t know how else to express the essence of my dissatisfaction with these - it probably goes into the Unix philosophy again. For example the:
Everything is a file.
rule - it’s a nice rule. A lot of OOP languages try to be purely OOP and the result is similar: everything is an object. But not in C++: something is an object, something’s not, it depends and sometimes you may as well toss a coin.
However it’s weird because for example Python is multiparadigm too and I don’t have such problems with it (I have some though)… So thinking about it, it’s probably because in Python it makes sense and is more elegant, designed this way from the start: You have a spectrum of structures covering all your needs evenly, whereas in C++ you basically only have these two native structures, which are very similar and exist only for historical reasons. Two is a very weird number - it’s not many, but it’s also not all the way to the “everything is X” philosophy. The rest is somehow filled in with the STLs, but that’s awkward because not always you have the standard library at hand.
So it’s just inelegant. C++ is a working solution, but ugly.
A lot of documentation is text only though. I think all these graphical representations are overrated too - at this level (small teams). The UML probably makes some sense as a communication tool in a corporate environment between a large number of people of different educations/languages etc. A lot of projects with a core team of a few people live happily with just text. Anyway, matter of taste probably.
You know, a lot of programmers say a good code is its own best documentation - not to be taken too seriously of course, but there’s a bit of truth. Just an inspirational quote from John Blow again:
Comments are code that never runs and code that never runs is a code that has bugs.
Just food for thought
Nice graphical documentation is always nice, but not always necessary (<- I can never spell this word correclty ).
Oh man, I hate these, it’s like mouse–.
Probably, but I refuse to play it now
(I used to be the biggest fan though, played all the games and DLCs, read all the books etc. I am contributing to OpenMW nowadays.)
Well, using one vs the other. Another example: exception handling… to what extent should I use exceptions vs the good old returned codes? I think I’ve never seen anyone use these consistently. There are some obvious cases where a lot of people feel like they have to use exceptions, then in the rest of the code they simply check return codes because it’s easier, and then there are places where they abuse the hell out of exception (catch all) - this can cause more damage than good. Then you have situations like when you have library A that is designed with exceptions and library B that isn’t and you have to somehow deal with it.
Weird syntax reminds me of Lisp… any experience with that? I still have it on my list of things to learn. Looks like a very nice language. Basically the closer something is to functional, the more appealing it seems to me… also the less I really use it in practice though.
Any opinions on why Haskell hasn’t taken over the world yet when everyone seems to love it? There was a recent article that explained this by the fact that basically what sells a language is IO. Actually implementing algorithms isn’t that difficult once you have IO sorted out. (Thinking about it it’s what brings me to C++ usually - the streams and standard strings.)
Actually I am very thankful that the most skilled programmers in this community take a bit of their time to talk to me If anyone else reads this, feel free to join in.
Since we have the split thread now, let me paste the rest of my rant:
Multiple meanings of the same keywords: const, static, … <- This is a symptom of an underlying problem:
many rule. Many rules make complicated systems with many ifelses prone to bugs, forcing users to remember unnecessary amount of information etc. C++ is such system. It inevitably has to manifest itself as
a big number of different keywords (also kind of the case), or
keywords with different meaning (case here)
related to OOP in general:
Setters/getter are real bad: basically whenever you want to add or delete a member variable, you have to do three things. Setters/getters are meant to validate/process data when accessed, but most data don’t need this. So all this usually encourages me to use structs when I should use classes (or make public member classes).
Inheritance leads to problems (circle-ellipse problem etc.), people and many design patterns usually resort to composition… but that’s basically what you do in C.
Templates: it’s an extra language within an already complex language - actually with the standard C preprocessor you now have three different-syntax languages in one, operating on different stages (runtime vs compile time). Again, this is many new rules you have to keep in mind - yes, you can do it, but it’s a mental burden, wasted brain capacity that could be used on solving actual problems, a potential for errors, and an additional thing for the compiler to implement. It’s kind of a similar case as with webdev nowadays - people try to replace PHP with JS and use JS for everything, since mixing all these languages makes no good.
I try to forget the ‘everything is an object’ approach even exists.
It’s a great marketing slogan but in practice it’s rarely ideal.
Also a lot of different languages have different ideas about what an object is.
The only thing they seem to be able to agree on is that objects have data (fields, member variables, properties) and operations (methods, member functions).
A lot of the time the language-level terminology blows away the theory terminology.
Actually from the standard’s point of view, all instances of all types are objects.
The standard’s definition of ‘object’ isn’t “must have methods and member variables”, the standard’s definition of object is roughly “anything that exists as a block of data and can fit in RAM or a register”.
(Strictly speaking it’s a bit more precise than that.)
From an OOP purist point of view, both struct and class declare classes and those are used to create objects.
Python’s ‘structures’ are illusions.
They’re basically syntactic sugar for what is effectively a class.
You could reimplement them using Python’s class functionality assuming python had some means of dynamic memory allocation.
If python can’t do dynamic memory allocation
Originally C++'s stance was not to bother with excessive syntactic sugar and just give the programmer the tools to build any data structure (a philosophy it inherited from C),
but in C++11 they gave in and introduced list initialisation and user-defined literals,
and then in C++17 they gave in again and added ‘tuple syntax’ (a.k.a. structured binding.)
Internally, C++ and Python are drastically different beasts.
STL != Standard Library.
The STL (Standard Template Library) was created by Alexander Stepanov in 1979 and developed into a popular C++ library.
When the standards comittee came to standardise C++, they looked at the STL and took a lot of inspiration from it, to the point that many of the early stdlib classes were almost identical, hence people sometiems informally label the stdlib as ‘the STL’, but doing so is incorrect because they’re two different things.
The only time I can think that you wouldn’t have it to hand is if you’re compiling for Arduino, and that’s partly because a lot of the data structures aren’t useful for AVR chips because they have such tiny amounts of RAM.
Ugliness is in the eye of the beholder.
Besides which, results and capabilities are far more important than not being ugly.
If you really dislike it that much then feel free to try to get D or Rust compiling for Pokitto, or write a C implementation of the PokittoLib, or stick to using MicroPython.
Sometimes I use it, but I probably don’t do the relationships properly.
Often I just draw bubbles with class names and connect boxes with function names to the bubbles.
Takes me less time than typing class declarations usually.
Sometimes, but not always.
The code can document what it’s doing, but not why it’s doing it.
If there’s a large system in play then it usually needs some explanation.
I admit to not documenting my code nearly enough because I don’t often work in teams or expect my code to be read, but if I’m making a library rather than a program then I’ll try to put more effort into documenting.
(Small note, ‘code’ is uncountable - it’s ‘say good code is’, the ‘a’ is ungrammatical.)
Another way of looking at it, a good compiler always removes unreachable code.
And documentation isn’t always in the form of comments.
That one I partly agree with you. I don’t like tablets either.
I also hate the word ‘apps’. If I tell someone I’m a programmer and they say “oh, so you write apps” I stare at them intensely and say “no, I write programs”.
If Skyrim is wrong, I don’t want to be right. :P
Different people have different conventions.
Pick a convention and stick to it.
The same as tabs vs spaces, the same as brace style, the same as ++x vs x++ etc.
This one’s easy on the Pokitto: exceptions are turned off :P.
The best approach is to try your damnedest to avoid error conditions in the first place (hence my advocation of references over pointer - don’t have to worry about null or dead objects or invalid pointers).
Otherwise, if you’re writing for desktop, it depends on how often you expect the condition to occur and whether you can handle it.
If it’s a rare condition or you can’t do anything about it then usually you want to use an exception.
For example, new throws an exception if there’s not enough RAM/swap left to allocate more memory.
The program cannot and should not attempt to do anything about this, the program should crash.
Fail fast - a crashed program cannot cause damage, a program running in a state of uncertainty can.
If it’s something frequent (e.g. ‘file not found’) then an error code is often better.
Newer C++ code will prefer to use std::optional which is like how Haskell uses Maybe.
If you do use error codes, prefer to implement them as enum classes (formally scoped enumerations), don’t use ints and macros or unscoped enums because those aren’t type safe.
That’s generally bad practice. (Not everybody writes good code.)
It’s ok if they’re logging the exception and then rethrowing, but otherwise cases where that’s warranted are few and far between.
It’s not about C++, it’s about C#, but one of my favourite articles about exceptions is Vexing exceptions by Eric Lippert.
He was on the C# compiler development team for several years.
Pointers can cause damage if abused, should we get rid of them?
Macros can cause damage, even unintentionally, should we get rid of them?
Every feature has a use case, every feature can be abused.
If you rule out a feature because it has the potential to be abused,
both C and C++ would be very bare languages.
The point of both C and C++ is not to hold the programmer’s hand.
They exist to allow the programmer to do dangerous things.
They trust that the programmer knows what they’re doing.
Sometimes the programmer knows exactly what they’re doing and they create something glorious.
Sometimes the programmer is an idiot and they break everything in the most horrible way imaginable.
Yep, that happens. There’s no avoiding it.
Some libraries opt for no exceptions because they want to be available for lower powered stuff, some do it because they’re used to C style and don’t know any better, some people object to exceptions because they think they’re slow (they used to be, not any more because people got smarter and invented a better exception system).
Equally, sometimes people pick exceptions for things that shouldn’t be exceptions.
You’ll find bad design in libraries for any language.
Nope. I thought about learning it once, but from what I’ve heard of it (code is data and data is code, among other things) I decided to put it near the bottom of my list.
It looks weird and cryptic, and I say that as someone who sometimes uses Haskell and has previously used Perl.
I don’t deny that Haskell can be sort of elegent when you understand it, but I’d never try to write something substantial with it.
I find that the elegance of a language has very little bearing on how usable it is.
Define ‘everyone’.
Part of the reason I opted to learn it was because it looks absolutely horifying and I wanted to be able to scare people.
Most of the people I’ve known take one look at it and say “what the hell is that?” (which I’ll admit to doing both before and after learning it).
I think the main reasons its not more popular are:
It’s full of undescriptive, short variable names
There’s a ridiculous amount of over-abstraction
Unless you’re mathematically inclined, it can be quite difficult
Programming without side effects can be really difficult, even if you actually understand monads
All looping is done with recursion, which is only more elegant than corecursion some of the time, other times it’s actually more confusing
No function overloading
It can be very slow and memory hungry
Instead of building new features into the language, it likes to make those features optional so you have to manually enable them using a specialised declaration within the code
Too many operators
Any string of symbols can be turned into an operator
For a supposedly elegant language it can be very verbose at times
instance Monad NonEmpty where
-- Guess which operator this is actually implementing
~(a :| as) >>= f = b :| (bs ++ bs')
where b :| bs = f a
bs' = as >>= toList . f
toList ~(c :| cs) = c : cs
instance (Monoid a, Monoid b) => Monoid (a,b) where
mempty = (mempty, mempty)
instance (Monoid a, Monoid b, Monoid c) => Monoid (a,b,c) where
mempty = (mempty, mempty, mempty)
instance (Monoid a, Monoid b, Monoid c, Monoid d) => Monoid (a,b,c,d) where
mempty = (mempty, mempty, mempty, mempty)
-- Repeat pattern ad nauseum for all amounts of tuples
But I still use it sometimes for data processing and maths stuff :P
I’m not sure I agree with that, but I would concur that Haskell’s basic console IO system is annoyingly esoteric and hard to work with, even with do notation.
Seconded. @FManga’s 3rd opinion was greatly appreciated.
Also despite continual disagreement, everything’s managed to stay civil, which is practically a miracle on the internet :P
Those rules are features.
If you started stripping them away, something would have to suffer for it.
I’ve yet to see someone propose a better alternative that still maintains the existing features.
They aren’t always used. There’s more than one way to do it.
The whole “OOP is this and must be programmed like this” that a lot of people seem to believe is utter hokum.
We’ve moved on since then.
People have realised that there are use cases and there are tools and you use the right tool for the right job, if you just adhere to a dogma then you rarely end up with the best result.
If used incorrectly.
Using inheritance to inherit a circle from an ellipse is an example of naive design.
That’s an old-fashioned ‘purist’ OOP approach, the world has moved on since then and realised that you shouldn’t use inheritance just because two things are related in the human’s mental model of them.
The problem here actually lies in a flawed mental model.
A lot of humans tend to think ‘a circle is a special kind of ellipse’,
but actually being a circle is actually a property of an ellipse.
Humans just use the ‘circle’ label for convinience.
Also, rather than just relying on a human mental model, what should really be considered instead is the use case and what the inheritance actually achieves.
Making Circle a subclass of Ellipse doesn’t really achieve anything that couldn’t be achieved better through making isCircle a property of the Ellipse (i.e. via a member function).
When deciding whether to give something inheritance, the Liskov substitution principle should be one of the main guiding forces behind the decision,
not a flawed human mental model of ‘dog is a mammal’ or ‘ferrari is a car’ because that’s too simplistic and theoretical - it’s not based on the constraints of the domain.
A lot of programmers only bother to learn how to use templates and never bother to write them, and it doesn’t burden them at all.
I beg to differ.
Templates actually help to solve certain problems faster.
Take std::vector for example.
Using templates, std::vector operates on all types. Without templates, you’d need to reimplement std::vector for every single type that you needed a vector for.
You’d have to have a std::vector_int, std::vector_bool, std::vector_char etc, all written in full.
With templates, you write once and it works for every type that meets the required constraints (e.g. the type needs to have a copy operator).
Here’s another example. In C++, if you want to know if two types are the same, you #include <type_traits> and static_assert(std::is_same<TypeA, TypeB>::value, "They aren't the same" and if you get a compiler error, the types aren’t the same.
I can’t name any other language that lets you do that.
That’s just the tip of the iceberg in terms of power.
Templates are one of my favourite features of C++ because of the sheer amount of capability it adds to the language.
Admitedly the balance will shift slightly in C++20 when concepts (similar to Haskell type classes) are finally added, but they are nethertheless incredibly useful.
As much as I immensely dislike both JavaScript and PHP, I can’t think of any particular reason why JavaScript couldn’t/shouldn’t be used for the backend of a website.
Perl used to have that role once upon a time.
Though I admit that I don’t like the idea of JavaScript being used to build desktop programs, but that’s more because I think JavaScript’s a bad language.
It’s too weakly typed and has too many arbitrary rules:
[] + [] -> "" Array plus array is empty string
[] + {} -> {} Array plus object is object
{} + [] -> 0 Object plus array is number?
{} + {} -> NaN Object plus object is… not a number…
Array(8).join("wat" - 1) + " Batman!" -> "NaNNaNNaNNaNNaNNaNNaNNaNNaN Batman!" String minus number is not a number!
(All examples taken from Gary Bernhardt’s 2012 talk “Wat”.)
No, it looks like it because here I specifically focus on what I dislike, but I’m going to keep coding in C++.
True, but code is usually comparably good (it’s designed to capture algorithms and data structures after all) while being much easier to create, searchable, can be automatically processed etc.
If an image really helps, I first try to make and ASCII version Then if it doesn’t work I create a real image.
good
No, they’re necessary - exceptions we can do without.
I’d rather says “how used” that “how usable” it is. The less used tools (Haskell as oposed to C++, GNU/Linux as opposed to Windows) are in my view superior by pure usability, but the actual popularity is a function of many more factors than just pure usability - more raw features wins over elegance in the market, the power of the creator to push the technology matters very much, the marketing, the support of hardware manufacturers etc. And then of course, popularity is a function of popularity (people make libraries for popular languages which in turn makes them more popular).
This is what it all boils down to - I’m an idealist, I’d like to have all my software free, elegant, minimal… even for the price of convenience, productivity. These are simply my personal values. On the other hand, as you say, someone else sees the beauty in the results and pure performance, not the internals. So… yeah
Well yeah, it’s feature creep. You can’t easily get rid of them once they’re there, but that’s where we are.
Yep, I appreciate this. You have much more experience with C++ and have a lot more to say about it, but I think the opinions and feeling of average programmers like myself are important too (especially when C++ is being used in projects targeted at learners), so I try my best to put them into words and leave them here. And let the expert have a comment on them.
Ok, you’re looking at programming languages with a mathematical definition of elegance. Here I’d agree with you: C++ is inelegant because it is not the simplest possible solution to a problem. That’s alright, it’s not meant to be that. The only programming language with that goal is this.
Instead, you could compare it to spoken languages. C++'s many rules can be a strength in the same way that having a large English vocabulary will help you better express yourself. In the same way, you have to do so carefully, taking the listener (the compiler and other people who will read your code) into consideration. You have no obligation to use your entire vocabulary when talking to someone, nor do you have to use every feature of the language you’re programming in.
Ah, JavaScript. If C++ is inelegant because it has too much stuff, that would make JS elegant because you use one thing to do two things.
First of all, in making desktop programs these unexpected features of the type system (almost?) never show up. In practice it’s pretty good, and is only a problem in two situations: Humorous / Python / Douglas Crockford talks and low-level code like emulators.
I like to tease my co-workers by saying Python has no reason to exist (tongue in cheek, it doesn’t really solve any problems that weren’t solved by other languages already), and Douglas Crockford bashes the language because it earns him money.
As for low-level code, something JS was clearly not meant for, the type system is workable and I actually prefer it to Java’s. No silly boxed and unboxed types that can’t be stored in a container. That is a bad language.
I’d say JS is elegant because the examples of strange additions can be understood knowing just two rules:
JS does not have explicit casts, but operators work on defined types so they cast things into types they can work with. When writing high-level code, you’re not too concerned about how, rather what the code does and it ends up working alright in practice even if it looks odd in contrived examples.
The binary + operator is defined for two numbers or two strings. Anything else gets converted into a string and concatenated. Pretty simple and I prefer it to PHP’s alternative.
In [] + [], arrays aren’t numbers or strings, so toString gets called on each. Arrays have a toString overload that returns its contents, separated by commas ([1,2,3] becomes "1,2,3"). An empty array becomes an empty string and the result is hardly surprising.
In [] + {} the result is not{}. Like before, toString gets called and the default result is “[object Object]”. You can overload toString to do something more useful, of course. Adding that to an empty string results in simply “[object Object]”.
Just like in C++, the meaning of “{}” depends on context. In C++ it can be an initializer list or a code block. In JS it is either an object or a code block. In {} + [], the parser understands it as an empty code block. That leaves + [] and the unary + operator only makes sense with numbers. Since it can’t work with anything else, like before, it calls toString and gets “”. It still can’t work with that, so it casts the string to Number and that returns 0. A bit surprising, but not the end of the world. It can’t cast “[object Object]” to Number, so no surprise: NaN.
The binary - operator is only defined for numbers, so trying to convert “wat” to a number results in NaN and the result is NaN. This is not surprising, what else could it reasonably do?
Misleading and confusing code can be written in any language. I find that people who dislike JS’s “quirks” do so because they are surprised it doesn’t behave like the languages they are used to. But if all languages behaved the same way, they’d all be the same language with minor syntax variations. Pointless… like Python.
My native language (Czech) totally sucks, it’s one of the most difficult to learn, but it certainly doesn’t give you more expressive power. It’s simply bad. Still very popular in my country
English sucks a bit less, but still big time. A lot of irregularities, multiple names for the same thing (coincidentally @Pharap just recently told me you can say quadriliteral or tetragon), multiple unrelated meanings of words depending on context (“can”), ambiguous sentences, weird rules with a lot of exceptions, …
Esperanto is beautiful - not perfect (probably still can form ambiguous sentences) but much closer, mostly thanks to scratching everything old and going for a new design. It’s completely regular, the same types of words have the same suffix (noun: o, verb: i, …), words are formed from a few basic words, etc. All that while keeping the expressive power (which is proven e.g. by the big amount of both translated and original literature). Still, it’s the least popular so far.
Lojban is probably beautiful too, but I don’t know much about it.
JavaScript
I don’t have too much experience, but kind of liked it. Though I never used it for any big program, to me it’s basically a prototyping language.
But to understand code you often have to read through several source files to understand how it all links together.
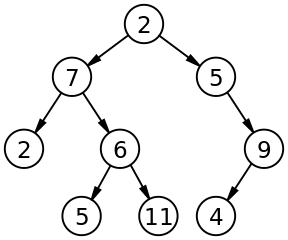
If you take a diagram that explains the algorithm, it’s often quicker and easier to understand than the code implementing it.
For example, the common tree:
That diagram is quicker and easier to understand than:
In my experience, most ASCII diagrams tend to be confusing.
They also tend to be mislabelled because they resort to using characters that are only found in extended variants of ASCII, like those found in code page 437.
It depends on the goal.
If you aren’t using dynamic allocation then you can usually do without pointers.
How much have you actually tried to write in Haskell?
It looks pretty, but it quickly becomes difficult to use for anything more complicated than tiny console programs.
I wouldn’t like to write a game with Haskell, I don’t think my brain could take it.
If Java’s motto is “everything’s an object”, Haskell’s motto is “everything’s immutable”.
Ironically a lot of the popular programming languages are ugly in one way or another,
but that ugliness often makes them easier to use.
A lot of really ‘elegant’ languages don’t get used because they usually trade away usability for elegance.
In the words of Bjarne Stroustrup:
There are only two kinds of languages: the ones people complain about and the ones nobody uses.
That is true, but I’d say usability is a big one.
If anything I’d say the availability of tools is also a critical factor.
One of the reasons people use C and C++ a lot is because there are many available compilers that target a lot of different systems.
The way modern compilers are designed, it’s usually relatively easy for people to add compiler support for a new processor because they don’t have to reimplement the language.
I don’t think marketing is that much of a contributor.
Once upon a time COBOL was strongly marketed, and now it’s almost abandoned.
People abandoned it because of its limitations. Other languages came along that could do the same job and do it better.
Popularity is indeed a feedback loop.
If people use a language and enjoy it, they spread the word about it.
If they don’t enjoy it or don’t like it much, they don’t talk about it.
I don’t talk about Haskell as much as I talk about C# or C++ because I find the latter two to be more usable.
People don’t opt to write a library in a language just because it’s popular,
they often opt to write a library in a language if they like that language.
One upon a time, I wrote an SDL wrapper for C# because I like SDL and I wanted to be able to use it with C# because I like C#.
It was a lot of work, but my love of the language justified it.
If I was driven by popularity then I would have figured out how to do the same in Java or Python.
I’m a mix of both.
I believe that code should look good because code that looks good is usually more readable,
but there must be a balance between looking good and functionality.
If there’s a conflict though, realism wins out every time.
If I got too hung up on making things pretty then I’d never get anything done.
Elegance is in the eye of the beholder.
I’ve seen some people claim that Java is beautiful and others claim that it’s inelegnt and needlessly verbose.
You say C++ isn’t elegant, but I think it can be more elegant than C depending on how the code is written, and it’s becoming more elegant with every new standard.
You could see it that way, but I think feature creep is defined by how often a feature is used, and personally I use a lot of those features, especially templates and const correctness.
A lot of the time not having them would make my life harder.
If you’ve looked around here, you’ll see how often I’ve said that not having access to C++11 features horribly limits the language.
C++11 introduced a lot of features, but those features didn’t creep in, they were designed to be useful and they are useful.
I won’t deny, C++ is not the best language to learn as a first language for the same reason C isn’t - it requires the programmer to understand the hardware to some degree, e.g. what RAM is (for pointers).
But when it comes to embedded systems, it’s the best choice because it has the right balance of structure and producing small code.
Most languages with comparable features to C++ produce larger or slower machine code, or require some kind of GC or overhead for their type system.
Also the goals of a beginner are different to that of someone who is experienced.
A lot of beginners like dynamic, weakly typed languages because they’re forgiving of mistakes.
Experienced programmers usually learn to dislike those things because they come to decide that a language that refuses to compile buggy code is better than having to hunt down bugs in valid code.
While I think of it, part of the reason exceptions have taken over from error codes in most languages is because error codes tend to clutter the code.
In the C++ version, all the error logic is implicit and the file will clean itself up,
reducing the cognitive burden on the programmer and reducing development time.
C++ likes to put the pressure on the library writers to design their code well so that library users don’t have as much to worry about.
:P
I really like this analogy.
Boxing and unboxing is actually quite common in GC’ed languages.
You’ll find it in Java, C# and Haskell.
Although C#'s type system allows containers to hold unboxed types.
The reason Java can’t is because it implements generic using type erasure instead of reified generics, and type erasure is an inferior system.
I have no idea what JavaScript does instead.
I don’t doubt that the rules make sense in context, but I question the wisdom of the rules in the first place.
Is implicit conversion to string common enough to warrant making it so ubiquitous?
I’d prefer a language that forces someone to write [].toString() + {}.toString() (or toString([]) + toString({}) if you’d rather) to achieve the same result and regards [] + {} as a type mismatch error.
I’m not a big lover of Python, but I generally agree with the sentiment that “explicit is better than implict” when it comes to type conversion.
There are exceptions (e.g. a reference of a child class being implictly convertible to the parent class), but overall it’s better to be explicit about what’s happening.
For me that’s a big negative. I greatly dislike implicit casts.
That said, I think there needs to be a balance, even if the right balance is hard to find.
Fundamental types (integers, floats, etc) should have implicit widening conversion.
JavaScript goes too far towards looseness.
Haskell goes too far the other way and is too strict about casting.
Fair enough, I misinterpreted what was going on.
I thought the REPL was calling toString in order to print the object and tried to ‘reverse’ that.
Syntax/type error as it would be in most of the other languages I’ve mentioned.
It depends on your background.
Most of the programmers I know well didn’t go into programming from a mathematics background and get on better with procedural languages than functional languages.
Personally I have very mixed feelings about maths.
In terms of notation I like things like set theory and group theory, but most mathematical notation I find to be too cryptic or confusing and I absolutely detest the wordy pseudo-latin that most advanced mathematics is described with.
Websites like ‘maths is fun’ show that maths can be explained in a simple and accessible way.
But mathematical papers are always written in a stupid way, like:
The product of multiplication of the arithmetical series beginning and increasing by unity and continued to the number of places, will be the variations of number with specific figures.
I feel like maths could be a lot more widely understood, but there’s too much pomposity and esotericism around it which makes it difficult for people to get to grips with it.
My favourite esolang is probably False.
Though I don’t like some of the decisions, like not having escape codes,
and ø being one of the symbols (I usually substitute £ when I write implementations).
LOLCODE is fun too.
I’ve heard quite a few people say that about their native language (e.g. German).
Most of them are because of foreign influence and evolution.
In the begining it was mainly just Latin and Greek influence, but over the years there have been tribes and wars and conquests so it’s been influenced by arcaic germanic languages and old french and all sorts of other things.
The best way to be good at English is to understand the etymology of words. Despite the number of influences, there are clear patterns and common prefixes and suffixes.
A lot of the exceptions come from either foreign influence (e.g. borrowing terms from other languages) or people going out of their way to buck trends.
I’d go careful with making the comparison between spoken languages and programming languages too literal.
Human language adapts and evolves to express a near unbounded amount of thoughts and feelings.
Programming languages only have to express programs - they have a niche job.
If English were a programming language, every word has to be defined like a function or class so theoretically everyone speaking English is constantly importing words from libraries.
(Because of this, it’s easier to pick up new programming languages than new spoken languages.)
That sounds like a recipe for creating ridiculously long words to express a simple concept.
You’d probably have to say the equivalent of “the smell of dust after rain” instead of being allowed to say “petrichor”,
or “the lump of wax formed in a whale” instead of “ambergris”.
That’s kind of how I treat Haskell for most things.
Not necessarily, prototypes tend to be noticably flawed.
After some time let me drop here some new points about templates, also as a response to a derailed thread:
Again, from a template noob’s perspective, and I don’t mean to offend anyone please.
Template syntax is completely wrong:
inconsistent:
Function definition doesn’t use the word function, but templates suddenly feel the need to stick template keyword in there, even if it’s not needed at all. Yes, classes use class keyword too, but templates could be recognized by the < and > brackets.
In many cases, C++ tries to reuse the keywords (e.g. using, see below) in order not to have too many of them, but in some cases suddenly (here) they drop a new one in just like that. I think they have big issues with agreeing on design goals.
unnecessarily verbose (doesn’t help readability at all): same as above, the template keyword doesn’t add any useful information that the brackets wouldn’t indicate.
extreme keyword mess: From the linked thread I learned that using has all kinds of many meanings about some of which I am very confused (maybe I’m just dumb).
Another big fail in my view: TIL that class and typename are the same thing when defining a template. I always thought there was some niché difference, but there isn’t? In which case this demonstrates what I already mentioned above:
They try to reuse a keyword class in order to not have a bazillion of them.
They find out it doesn’t work, so they throw in a new keyword typename, but they have to keep the old one in for compatibility.
The result is the worst possible situation: multiple-meaning keywords with confusing meanings plus a new keyword.
I’d make templates something like this:
class MyClass<type T, int x> { ... };
int MyFunc<type T, int x> { ... };
So, the problem is C++ is trying to both
Stay the good old, tested, widely supported language like C. AND at the same time
Actively introducing the most modern features and ideas.
I’d call the result an abomination that resembles an animal that tries to evolve but keeps all it’s previous forms, so it has fins and wings and horns and a trunk, just in case. Now being general purpose is not bad, but it’s getting there the wrong way, in a way that hasn’t been properly planned.
So, C++ definitely has it’s place – in legacy systems that need to be updated with modern features. But for new projects a new language should be preferred.
“C++ has better support” (e.g. it’s the only option on Pokitto if you want performance) is an argument for making use of it, but not for it’s good design or quality.
@Pharap I suppose what I am talking about, e.g. the syntax problems, are very similar to what you told me your problem with mathematical notation/language was – they both suffer from carrying along their history, would we agree? I guess what’s surprising to me here is that you, as the advocate of modern replacing the old, don’t advocate for a completely new language that isn’t burdened by history – such as Rust. (EDIT: just learned Rust doesn’t support OO, is this the reason?)
(Of course you can turn this argument on me as well. I guess I am learning too, and I am more willing to admit mathematical notation could use some refresh, maybe a standardization even, something not unlike a programming language specification.)
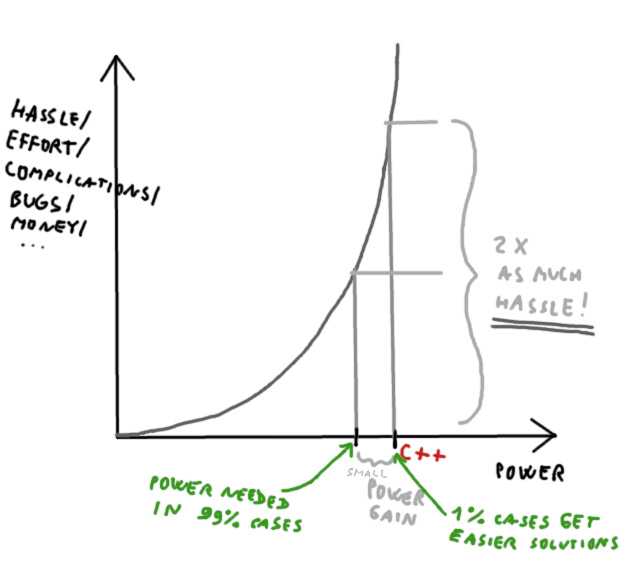
That’s totally fine, don’t get me wrong, in no way am I advocating for C++ to be more approachable. I am only talking about possible safety and avoiding the probability of errors and a simpler design without losing too much power. Let me try to tell it with a picture:
Function syntax was inherited from C,
but template syntax was a new addition created by a different person.
It was most likely added in a way that made it easier to integrate into the compiler.
Finding a ‘template’ token and then switching to template mode was most likely easier than getting part way though a function and having to suddenly switch to template mode.
Using an alternative would complicate the compiler.
For example, under the syntax you’re suggestiong, if a return type was also a template parameter:
T constructT<type T>(void)
{
return T();
}
Suddenly T is a nonexistant symbol at the point it’s encountered, and you need to get past its first usage to make sense of it.
That’s easy enough for a modern compiler that builds a parse tree,
but back then computers didn’t have enough memory for a proper parse tree of the entire program,
so they’d often skip the parse tree and just work on the tokens.
That’s something we take for granted these days.
Today multi-pass compilers are cheap and easy to do,
but back then the single-pass approach was far more common.
Most C++ idiosyncrasies like this can be explained by unfortunate history and age.
It’s easy to make judgements in hindsight, but you need to make judgements based on the historical context otherwise they aren’t fair - it’s like saying “why didn’t medieval people just build engines for their carts”.
Unless you can demonstrate how to modify the grammar of C++ and/or get an existing C++ compiler to recognise that alternative, you should be careful about making such a statement.
Language and compiler design are complex,
and modern languages have the benefit of hindsight.
When C++ was devised, there were far fewer languages to take examples from.
Again, it makes sense in historical context.
They try not to add new keywords since the language was standardised, but templates predate the first standardisation (C++98) so that wasn’t a concern back then.
Languages aren’t just brought into existance, they evolve.
It only has about 4 uses.
using type alias
using to introduce a specific name from a namespace into a scope
using to introduce parent members into a child class (which is really a special case of the former)
using namespace to introduce an entire namespace into a scope
And this complaint contradicts your earlier complaint about the keyword template not being needed.
You either give the same keyword multiple meanings, or you introduce new keywords - you can’t have it both ways.
Originally they didn’t want to add another new keyword so class was used,
but typename was used for something else and they decided to repurpose it for use in another context because they thought it fit better than class,
but they couldn’t remove the use of class because it would break backwards compatibility with pre-standard programs.
Again, an accident of history.
As for the impending “why didn’t they use typename in the first place?” - people don’t always think of everything immediately, it takes some failed attempts to get the best solution.
Again, typename already existed before it was repurposed, they didn’t add it just to replace class in that context, and it wasn’t the same person making the decision - class was Stroustrup’s decision pre-standardisation and typename was the standards committee’s decision after much deliberation and a fresh pair of eyes looking at the situation.
If Stroustrup had already had typename and realised it was a better candidate, he might well have used that from the start, but nobody is perfect.
It’s mainly trying to do the latter these days.
They’re not afraid of breaking backwards compatibility to a degree,
but they don’t want to fundamentally change existing features because that mean people have to unlearn things,
and suddenly discovered something that has worked for 20 years suddenly doesn’t work is more offputting than having new features to learn.
Then go ahead and use one.
You could get D or Rust working for Pokitto if you really wanted to.
Nobody is forcing you to use it.
But I stand by C++ because I know what it’s capable of.
In the words of Bjarne Stroustrup: "There are only two kinds of languages, the ones people complain about, and the ones nobody uses."
Yes, but C++ tries to improve - to introduce better syntax for old ideas, whilst not getting rid of those old ideas so that legacy code can still use them.
For example, modern programs should avoid unscoped enums and use only scoped enums - effectively unscoped enums should be treated as if they were removed, but they haven’t been removed because it would break older programs.
Maths doesn’t do that nearly enough.
Also, C++'s history is still relatively short and recent.
I don’t dislike Rust. I don’t say people shouldn’t use it.
I’d be willing to give it a try if I had the time.
But I like C++, and I think that it’s a good language despite its faults.
Personally from what I’ve seen of Rust I’m not a huge fan of the syntax - too many abbreviations.
(And I say that as someone who sometimes uses Haskell.)
I prefer Haxe’s syntax to Rust or D.
C++ is perfectly safe if you avoid dangerous features.
But often I find people refuse to use the safer (typically more modern) features and insist on writing C++ like it’s C,
which is where the really dangerous things creep in.
For example, I still see people using int with defines instead of using scoped enums.
Even C had unscoped enums, but some people would rather shoot themselves in the foot and blame the language for letting them.
If you can produce a specification for a language that it just as powerful but with a simpler syntax, then by all means propose it.
It’s easy to cricise something, but it’s much harder to produce a better alternative.
Sometimes even seemingly obvious alternatives have larger implications.
It’s one thing to imagine a language, it’s an entirely different thing to sit down and define it in BNF and/or be sure that it’s possible to create a compiler for such a language.
And of course, you’d have to know everything C++ is capable of to be sure you managed to match it.
Being able to match the power of type traits alone would be a significant effort, and more than most languages could manage (without reflection).
That sounds like you’re confirming all I am saying though You’re explaining C++ has these issues for historical and compatibility reasons, and that’s what I’ve said as well, so we agree.
The thing is we can’t dismiss issues because we know why they happened. The important thing is they’re there.
Of course I can’t make a better language – I’ve helped write a small compiler some years back so I know it’s hard as hell – but the critic never has to be better than what he criticizes (otherwise none of us would be allowed to complain about 99% of the things we use). Still I can see the flaws and possibly a better alternative.
Basically to me it’s just surprising you do see the flaws as well, but somehow gently sweep them under the carpet and keep advocating exclusively for C++ and OOP in all situations – or at least that’s how I honestly perceive it, please excuse me if I am wrong.
My view is that all current languages suck, even the ones I prefer, and I try to pick the one that will suck the least for what I am trying to do, and since Pokitto programs are rather simple, I mostly tend to C or C style C++. But for a big PC game I’d go with C++, OOP, templates, design patterns and I’d be trying to program in the way you’re doing it. I just don’t think this is a good approach for everything and sometimes it’s okay to throw in a macro instead of a template, or use classless style.
I’ve been thinking about whether Rust can be compiled to C++ or C, which would allow me to use it for Pokitto. Just to try it out and learn the language, otherwise I think C++ is more than good enough for us here, and I will be using it. Although maybe combined with C etc., again because it’s more KISS.
I don’t necessarily agree that they’re issues though.
Personally I like the template syntax, I don’t think it’s that much different to the C#/Java style approach.
Certainly not different enough to split hairs over.
Most of the time behaviour, style and convention matter far more to me more than language syntax.
There are two choices: accept that things are the way they are and live with it, or use a different language.
Some things are so deeply ingrained that you simply can’t fix them without breaking a lot of existing code.
it’s better to accept the flaws and move on with things.
If I went around getting upset about every flaw in all the languages I use then I’d never get any work done.
The world is full of things that I don’t like,
but I complained about all of them then I wouldn’t get very far.
I choose to try to only complain about things that I can change somehow, otherwise “shikata ga nai”.
If I can’t fix it or propose something better then there’s no point getting worked up about it.
Besides which, the benefits of C++ massively outweigh the drawbacks.
If I really wanted to write an interactive webpage and JavaScript was my only option then I’d use it,
because at that point the need to use it would outweigh the many, many flaws with it.
I don’t agree with that at all.
There’s a lot of languages that I really like.
(And some that I really dislike).
I would never say all programming languages suck.
There are some nice, simple languags that are terribly limited,
there are some ugly, complex languages that are really powerful,
there are simple languages that are bad and ugly,
there are complex languages that are powerful and still have decent syntax.
There’s no perfect language, but most languages have a mix of pros and cons.
I’m glad I take that stance though.
If I weren’t willing to brave ugly syntax then I’d never have learned Haskell, and that’s been a real eye opener.
In fact, if I had let myself get put off by VB’s syntax or the stark difference between C#'s syntax and VB’s syntax then I’d probably have never even started out on the programming road.
If I hadn’t been willing to try to overcome my great dislike of maths then I wouldn’t understand vectors, matrices or sets.
Sometimes you just have to put up with things the way they are,
and sometimes if you do that then the rewards are well worth the trials you face to get those rewards.
I can think of times when I’d use macros, and there have been one or two times when I used macros (though few were actually worthwhile),
but I can’t think of many situations where I’d use a macro instead of a template.
Templates have too many advantages over macros,
and most of the time they solve different problems.
As for going classless, I honestly do not see any argument for this:
struct Vector
{
int x;
int y;
};
double getMagnitude(Vector vector)
{
return std::sqrt((x * x) + (y * y));
}
Vector v = { 4, 5 };
std::printf(getMagnitude(v));
Being superior to this:
class Vector
{
public:
int x;
int y;
double getMagnitude(void) const
{
return std::sqrt((this->x * this->x) + (this->y * this->y));
}
};
Vector v = { 4, 5 };
std::printf(v.getMagnitude());
The difference is negligable and it takes hardly any time to explain the difference
but the semantics of the second are a major improvement over the former because they signal some important information - that the magnitude of the vector is an instrinsic part of the vector, not a separate concept.
You pay a high price for that simplicity - you pay in terms of type safety and readability.
I have come across a few sources that seem to capture the wider philosophy I’ve been trying to present. I would like to share them here as a footnote – a context, for those who would like to read about it.
The first is the suckless philosophy and manifesto:
This ended up being a lot longer than intended.
Originally I was just going to give a two line answer.
I think the second was more interesting than the first.
I’d like to point out this is why C++ is a good language.
C++ is the balance between the low level and the high level.
If you want to manipulate bits, you can.
If you want to be abstract, you can.
Garbage collected languages like C#, Java, JavaScript, Python, Haskell are what allow people to get lazy.
You can’t see the memory management, so you don’t care about it.
Low level savings don’t matter, because the garbage collector and the runtime environment are so large and complex that the savings you’d make are typically tiny by comparison.
That said, I don’t agree that ‘small, bits and hacks’ are inherantly ‘beautiful’.
I don’t really have a concept of beauty as such, but if I did I’d say ‘balance is beautiful’.
Not too complex, not too simple.
Weigh up the benefits against the drawbacks, decide what matters the most and pick the right tool for the job.
Everything is a tradeoff, every feature has a cost, you just have to decide if it’s a price worth paying.
(Also I’d quite like to be able to be self-sufficient, but it wouldn’t be practical for me.)
I think the former has some good points but is also flawed.
For one thing, I’ve never met a programmer who genuinely thought more lines of code means better code.
A lot of people don’t improve their code’s quality because either:
They don’t know how
They don’t have the time
They don’t agree on what ‘good quality’ is
They can’t be bothered because it would take a lot of effort
They don’t care because the code does what they want it to
(and they only care about whether the code works for them, they don’t care about other people who want to use it)
But throughout this, the article doesn’t actually define what is complex and what is simple.
For example, is a tree data structure complex or simple?
On the one hand, tree operations like node rotation are painfully complex,
but on the other hand trees are often the best tool for certain specific jobs and the concept itself is quite simple.
And what about smart pointers?
Internally they’re quite complex, but using smart pointers is much simpler than handling the memory allocation yourself.
If it wasn’t, you wouldn’t get as many languages that have reference semantics (essentially another name for smart pointers) in place of actual pointers (e.g. Java, C#).
Sometimes what appears to be a complex solution is actually simpler than alternative solutions.
Sometimes what appears to be a simple solution is actually more complex than it first appears to be, or it starts to break when the goalposts move.
Often it’s a matter of scale.
The programmers who end up writing big, messy programs often don’t start with those big, messy programs.
Often they start by writing something simple, that does just one job, and they only intend it to do one job, so they start off by using simple solutions that don’t scale well.
Then they think “it would be cool if this did this”, and feature creep kicks in and suddenly they have a massive blob that they should have refactored 15 features ago.
If they’d stopped and said “let’s tear this up and redesign it so it’s scalable” near the beginning and then invested time in figuring out how to make it flexible and scalable to accomodate new features, they’d end up with something much more robust.
It might still be moderately complex, but it would probably be less complex overall and still be maintainable.
Also I find it ironic that they link to the ‘duct tape programmer’ article,
because it’s that kind of duct-taping that produces truly messy monstrocities.
Don’t get me wrong, there are people who do go overboard with design patterns and things, but the problem is the person’s thinking, not with the tools themselves.
The problem comes either when people want to use things to show off what they can do or when people don’t actually understand when to apply a certain technique.
As the saying goes “when you have a hammer, everything starts to look like a nail”.
If someone goes out and murders someone with a kitchen knife (or a hammer, or a screwdriver),
the solution is not to ban kitchen knives (or hammers, or screwdrives).
If someone wants to try to hammer a nail in with a screwdriver, the answer is to explain why a hammer is the correct tool for the job.
(Multiple inheritance does have a purpose, it’s not the spawn of satan, but it’s important to realise there’s a time and a place for it, and that it is very rare to need it. I don’t think I’ve ever needed it.)
In fact Zawinski’s “you’re not here to write code; you’re here to ship products.” and “unit tests are not critical. If there’s no unit test the customer isn’t going to complain about that.” are some of the things that lead to modern software being overgrown.
People get so obsessed about getting a finished project out on time that they stop caring about how much memory it uses and how many bugs it has.
(That’s probably the biggest problem with commercial software - deadlines.)
They end up grabbing 10 different libraries and trying to glue them all together because they think it will be quicker,
instead of thinking “actually, it will take longer, but we could cut out 4 of those libraries if we wrote our own version with fewer features”.
(Libraries aren’t bad, but using too many is.)
Like I said before, what really matters is balance.
Decide which features and which goals are the most important,
decide which tradeoffs you’re willing to make.
Don’t be afraid to do something complex if it has desirable qualities (e.g. flexibility, scalability).
Don’t use a tool just because you can, use it because it does something that you need.
For example, I don’t use templates for the hell of it.
I use templates because writing a single fuction/class that works on multiple types is typically less effort than writing really similar code several times over for different types.


 ).
).
 Then if it doesn’t work I create a real image.
Then if it doesn’t work I create a real image.