
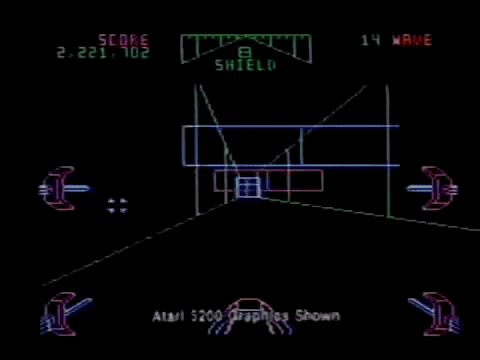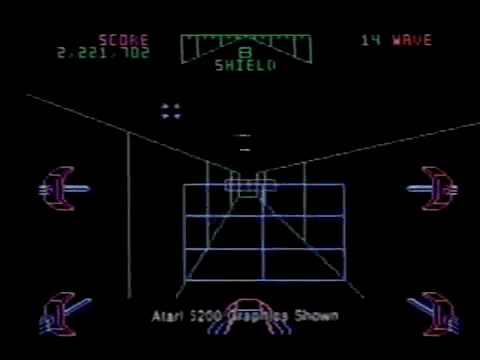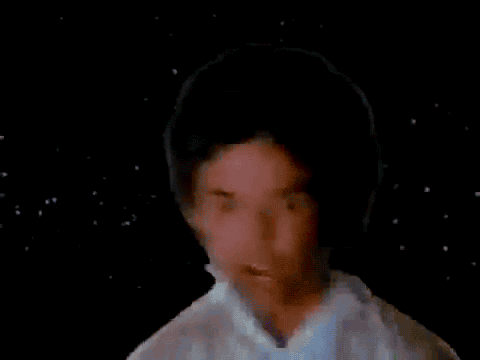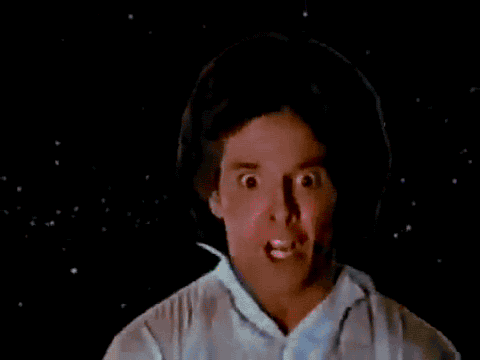
adding more elements would obviousy make it look more organic right now it has 10 segments each 8 pixels long
EDIT:
Here is another example with 30 segments

EDIT2:
Another quick gif where the rope segments get bigger and further apart

adding more elements would obviousy make it look more organic right now it has 10 segments each 8 pixels long
EDIT:
Here is another example with 30 segments
EDIT2:
Another quick gif where the rope segments get bigger and further apart
Cool! Is it demanding on performance? I can see this potentially being used for some nice effects.
EDIT:
Switching from float to fixed point should help to make it faster.
I would guess so. I used some floating point math to get it to look this wavy. However I didnt make an effort to optimise and I have no Idea how this runs on Hardware.
The concept is quite scalable in the sense that you can choose how many segments you want to have and how often per frame you want to calculate the positions of the segments since this is only a heuristic.
Calculating it only one time per frame seems fine but you can see the tail of the rope moving slightly for a good second after you stopped moving
Let me check how it runs on Pokitto for you.
You’ve made a very nice framework, switching to fixed point shouldn’t really be a problem for anybody. I imagine the performance would matter if you had a lot of strings, like an octopus boss or something 
EDIT:
Runs very smooth even now (sorry, recorded via webcam  ):
):
@Xhaku Cool stuff! Btw I am looking into why the Pokitto has not arrived yet.
I have had bad luck with shipments lately, it seems 2 shipments have gotten lost last week.
Thanks. I am having lots of fun with the simulator so it’s no big deal. i am starting to think that I’m cursed however. my last 3 packages didnt arrive. the 1st item was destroyed in shipment. the 2nd item was sent 3 times after which i found out that the ebay seller sent it to the wrong adress (i verified that i entered the correct one) and never bothered to send a 4th time so i got kinda nervous when the pokitto didnt arrive 
Hahaha! Your luck is even worse than mine.
Posting packages through “postal services” is like:
Made it more C++11-ish:
I barely understand some stuff you did  but you definitely made the angle situation more readable. Guess im gonna have to look structs up and what “this->direction” does.
but you definitely made the angle situation more readable. Guess im gonna have to look structs up and what “this->direction” does.
Forgot to mention, I didn’t check if it actually compiles so there might be a mistake or two.
I’ll compile later and correct any mistakes if I find any.
struct is the same thing as class, the only difference is that everything in a struct is public by default, whereas everything in a class is private by default.
I tend to only use struct if I’m sure I want absolutely everything to be public, otherwise I use class and mix the accessors.
this-> just accesses the class’s member variables.
Using this-> is optional, so most people don’t bother using it, but I make sure to always use this-> because it makes it clearer that I’m accessing a member variable and not a global variable, local variable or function argument
That way when you take a function out of context you don’t have to sit there guessing “is this a global or a member variable?”.
You know that anything with this-> is a member variable,
and anything else is either a local variable, a function argument or a global variable,
and you’ll be able to see where the local variables and function arguments are defined,
so you’ll be able to deduce that anything else must be a global variable.
If there’s anything else you don’t understand then I’m happy to explain it.
To preempt one of the things you’re probably going to ask, this:
Segment(float x, float y, int direction)
: x(x), y(y), direction(direction)
{
}
Is (roughly) the same as this:
Segment(float x, float y, int direction)
{
this->x = x;
this->y = y;
this->direction = direction;
}
Which is the same as this:
Segment(float _x, float _y, int _direction)
{
x = _x;
y = _y;
direction = _direction;
}
So hopefully that clears that up.
I’d like to point out that it’s bad practice to use a leading underscore in an identifier beacause according to the standard:
Each name that begins with an underscore is reserved to the implementation for use as a name in the global namespace
If you have any questions whatsoever, feel free to ask,
either here or in a PM, whichever you’re more comfortable with.
(That goes for anyone else reading this too.)
Thanks fo the explenation. The only thing i still dont get is all this Valuetype stuff in the Point struct
template<typename Type>
struct Point
{
using ValueType = Type;
ValueType x;
ValueType y;
Point(void) = default;
Point(ValueType x, ValueType y)
: x(x), y(y)
{
}
};
is this comparable to generics in java?
Yes, AFAIK it’s two names for the same thing.
The template<typename Type> part is a template declaration.
Templates are C++'s implementation of generics, so it’s similar to Java’s generics system.
The implementation is quite different from Java’s, but the basic idea is the same - you have type arguments that allow a class or struct to work for multiple different types.
If you’re used to Java’s generics system then you can think of them as being the same but with different syntax.
Truthfully the implementation details are _a lot differen_t and at some point that difference will become important,
but for now you can think of them as the same thing but with different syntax.
(I’m happy to explain the differences, but it would probably be a very long explanation.)
Beware assuming them to be the same thing,
the implementations are vastly different and C++'s template system is far more powerful.
Edit:
Importantly, thanks to Java’s Type Erasure mechanism,
when a Java object talks about T it’s actually using java.lang.Object with a load of casts everywhere.
In other words, List<String> is the same as List<Integer> and both are actually just List<Object> with some added runtime (i.e. performance penalty) casts.
For more info see Wikipedia.
Type erasure is a cheap and nasty approach to generics.
C# learned from this mistake and used reified generics instead.
C++ doesn’t have this issue because every instantiation of a template is a distinct type.
All type checking is done at compile time - there’s no extra runtime cost.
using ValueType = Type creates what’s called a type alias.
It means that from then on, ValueType is equivalent to Type - both identifiers represent the same type.
I could have not bothered with the type alias, and just written this:
template<typename Type>
struct Point
{
Type x;
Type y;
Point(void) = default;
Point(Type x, Type y)
: x(x), y(y)
{
}
};
Which would have worked just as well, and for the sake of your program wouldn’t have made any difference.
I included the alias because it makes obtaining the type of the members easier in certain circumstances.
For example, if I was using the definition of Point<T> without using ValueType = Type;, and then did:
using IntPoint = Point<int>;
I would have no easy way of retrieving the int type.
(There are ways, which I’ll demonstrate later.)
However, if I used the definition of Point<T> that includes using ValueType = Type; then I can do this:
IntPoint point = IntPoint(4, 5);
IntPoint::ValueType x = point.x;
So basically, it provides a way of accessing the type parameter when you aren’t the one supplying it.
This is quite common for templated types from the C++ standard library.
For example, here are the aliases that std::array defines.(Which includes value_type - the standard library prefers ‘snake case’ for its types, I usually prefer ‘Pascal case’ unless I’m trying to make something compatible with the standard library.)
Now, if I hadn’t defined ValueType, there are still two ways I could have obtained the type.
Firstly:
IntPoint point = IntPoint(4, 5);
using ValueType = decltype(point.x);
ValueType x = point.x;
And secondly:
IntPoint point = IntPoint(4, 5);
auto x = point.x;
(Technically this second way only works for variables and certain specific situations.)
So, why is the using ValueType = Type; approach used despite having these other two methods?
There’s three reasons.
Firstly, because auto and decltype were both added in C++11, prior to that in C++03 and C++98 they didn’t exist, so the type alias approach was the only viable approach.
(In fact, using didn’t exist prior to C++11. Originally you had to use typedef, which has much more confusing syntax.)
Secondly, because it’s a better way of making the type self-documenting.
By using IntPoint::ValueType explicitly, it makes your intent more obvious - it makes it clear that the type is intended for holding values.
(Using auto everywhere can start to make the code look a bit cryptic in some cases.)
And thirdly, sometimes it’s just easier to work with than the alternatives.
Read dangerous 
Templates is very time consuming, but sooooo worth it when it finally manage to compile
How exactly are they dangerous?
I can’t think of anything dangerous that they can achieve that isn’t already possible in non-templated code (like messing around with void *s, or doing type-punning - both of which creep into the nasal demon realm).
Time consuming to learn or time consuming to make?
In my experience they usually take the same amount of time as a specialised class,
unless you’re doing something especially difficult (e.g. fixed points, SI units).
They can take some time to truly understand, but they’re well worth knowing.
I think many people misconstrue normal template usage as being like meta-template programming,
when really it isn’t.
Most of the time, it’s no more difficult than the Point struct that I introduced to this kinematics demo.
Meta-template programming isn’t something people are going to need often (especially with C++11’s introduction of constexpr, which allows many former meta-template classes to be replaced with functions).
Really though, with the exception of a few rare cases,
meta-template programming typically isn’t much different to using higher-order functions.
If you can sit through LYAH from chapter 1 through to chapter 6 then meta-template programming should be a doddle in 80% of cases.
Factorial as a function:
constepxr std::uintmax_t factorial(std::uintmax_t n)
{
return (n > 0) ? 1 : (n * factorial(n - 1));
}
Factorial as a meta-template:
template<std::uintmax_t n>
struct factorial
{
static constexpr std::uintmax_t value = (n * factorial<n - 1>::value);
};
template<>
struct factorial<0>
{
static constexpr std::uintmax_t value = 1;
};
The syntax is different, but the concepts are the same:
Pattern-matching, Recursion and piecewise functions.
(And arguably recurrance relations, but that’s just a fancy term for a recursive function that generates a sequence.)
To make! Usually it’s simpler to use - thought it can be a pain in the ass because of the diagnostics messages.
Well, I’m not an expert C++ programmer either; just talking from my limited experience, and I’m certainly not a genius programmer either; and I feel like my focus capacity has been downed for
I rely more and more on template, and they’re definitely an indispensable tool for me.
Still, I maintain that, for me, thinking in “template” -especially when conceiving them- is harder than template-less code.
Also, I’m not talking about basic stuff like std::max and Points, etc! I’m skilled enough to tackle them as easily. However, for the more complex stuff I do struggle much more with template-based solutions (funny thing is that I’m also much more satisfied when achieving something hahaha) than with non-template-based ones, with my everyday adventures in C++.
There are some reasons for this:
I love template programming because it’s so rewarding when it works. Compile-time checks are just awesome, and it’s like seeing a puzzle making itself haha
More power is always more dangerous, all I’m saying  It’s a double edged sword.
It’s a double edged sword.
More power implies for example a bigger probability of misuse, compiler bugs, confusion, … means more work, complexity, fewer things we can assume about the system, …
I’ve once listened to an interview with CMake devs and they said they specifically didn’t want to use an existing general purpose language and rather made their own computationally limited language because if they used e.g. Python, people would start abusing it and messing things up. They’d have to think about all the possible imaginable things users could potentially do. So I think it’s important to also think about not making a tool more powerful than it needs to be.
I guess I just wanted to point out this general principle, nothing personel against templates. You know, I’m always the antithesis 
We’re going off topic a bit, so I think this is going to be my last post on templates unless @Xhaku is particularly interested.
I still might branch some of these off into a separate thread anyway, we shall see.
I wouldn’t really call myself an expert either - I don’t think that’s for me to judge, I think it’s for others to judge.
But I think it’s safe to say that I probably have more experience with templates than most.
I was waiting for someone to mention this.
SFINAE is feared because it’s a big scary acronym and the phrase “substitution failure is not an error” only makes sense in context.
I’m often forgetting it because it’s rare to actually have to invoke it unless you’re writing a particularly complex template library.
Fortunately I wrote a relatively simple explanation-by-example to remind myself when I forget.
It’s not that complicated really, basically the rule is:
“If a template parameter in a template function can’t be properly substituted without encountering a subtitution error,
that doesn’t cause compilation to halt.
Instead it causes the compiler to look for other function candidates instead
An error only occurs when no suitable candidates can be found.”
Or more simply:
If the compiler can’t substitute a template parameter on a function, it keeps trying other functions until it finds a suitable match or it runs out of candidates.
The trick is to think of type in terms of their interface (functions, members, type aliases), their rules (invariants, preconditions, postconditions) and their roles (container, functor).
Honestly the best recommendation I can make is learn Haskell.
Even if you never use Haskell after learning it, the Haskell way of thinking applies really well to templates.
Haskell is essentially built around the kind of type manipulation that templates were built for.
This is improving thanks to static_assert.
For example, here’s a case of using static_assert to provide a nicer error message for an invalid template instantiation:
If Integer + Fraction is greater than the number of bits available in uintmax_t then the type cannot be properly formed.
Normally this would be a silent bug,
but thanks to static_assert, such an instantiation won’t compil and, the compiler will spit out the error message:
“Platform does not have a native type large enough for UFixed.”
Definitely. I’m always pushing features that improve type safety.
If everything is type safe then there are some bugs that you just don’t have to worry about anymore.
One of my favourite examples being with scoped enumerations vs unscoped enumerations:
EnumType value = 5; // Error: 5 is not a value EnumType
EnumType value = EnumType::SpecificValue; // Success: meaningful and without fear of runtime bugs
Programming is all about puzzles.
A darn sight more puzzling than Zelda dungeon puzzles. :P
If we stopped using powertools then nothing would get done.
Never using templates because they’re ‘powerful and scary’ would be like never using pointers because you can corrupt RAM with them.
The C++ philosophy is to trust your users, not to treat them like babies who need childminding.
I think that’s a big insult to their userbase - it sends out the message “we don’t trust you to use these powertools responsibly, so we’re not giving them to you”.
It’s like saying “we’re not going to give you a kitchen knife because you might cut yourself or stab somebody with it” - incredibly patronising.
There will always be someone who abuses the system,
no matter how much you try to prevent it or limit it.
It’s better to provide the power to the people who know how to use it properly than deny it to them just because others can’t handle that power.
In fact, if anything I would have thought you’d take the ‘power’ approach rather than the ‘sandbox’ approach because Linux takes the ‘power’ approach and Windows/Mac take the ‘sandbox’ approach.
Mac and Windows say “let’s hide the console and the programming tools from everyone because they can’t be trusted to know how to use them”.
Linux says “trust the user with all the powertools, centre the whole system around the power of the command line”.
Yes @Pharap, let’s not DDOS this thread, I’ll try to reply in this place:
I’ve been looking into templates thanks to this thread and I feel I have some criticism I’d like to share again. (@carbonacat or anyone else can join in too of course)