Sorry I meant STD string not c string, there more dynamic
1 Like
Might I interest you in std::char_traits?
As of C++11 std::string is guaranteed to know the size of the string in constant time.
Dynamic allocation isn’t a bad thing, you just have to be aware that it can fail and be able to handle it when it does.
Also, rather than storing each line you could just maintain a list of the indices of newline characters, which would mean you’d only have to worry about the allocation of that list, and not the allocation of the lines themselves.
To be honest std::string is actually easier to work with than bare null-terminated char arrays.
You don’t need to understand pointers and you don’t need to worry about null-termination.
Null terminated char arrays are much more difficult to work with, and the fact they’re so commonly used is merely an accident of history.
Rough proof-of-concept of a typing game with a chorded-circle-thing-keyboard:
TypingGame.bin (54.8 KB)
Edit: source code
3 Likes
My progress is going more slowly because I’m busy with other things.
I’ve just templated everything so it’s possible to have a backed that generates char32_t and a frontend that consumes char.
This only affects the source, the binary’s behaviour is still the same for now.
Edit:
Updated again. Now I have an actual grid-based keyboard.
The text editor itself is still grid based and the keyboard doesn’t render non-char commands, but otherwise it’s somewhat functional.
1 Like
Can’t wait to try it  I’ll leave you a comment.
I’ll leave you a comment.
1 Like
Sorry, been away all day… I like it, at first it’s real difficult to type anything as I expected, but I’ve been able to get into it and I believe if it was polished and I spent one day playing this game I could be faster than with my keyboard.
At first I got stuck at typing E – you have to press A quickly twice, that was tricky, and then also there are difficult letters… e.g. how do I type M without using 3 fingers?  Maybe I’m missing something. And also – what about the rest of the characters, like brackets, lowercase letters and so on? the tree would get deeper and wider.
Maybe I’m missing something. And also – what about the rest of the characters, like brackets, lowercase letters and so on? the tree would get deeper and wider.
I think in order to solve these, there would have to be some kind of state while traversing the tree? Like when you open a subtree by pressing a button(combination), you wouldn’t have to keep holding the buttons. Instead of having a single button combo for each character, these would become maybe pairs of consecutive combos – when memorized, it would still be very fast as each symbol could be typed with only two (multi)presses.
And this also made me think about a music game like Guitar Hero… bytebeat anyone?
Yeah, it would be easier with a bit more polish, I just wanted to have an idea if the theory is sound.
To type E, press and hold left, then A.
M is Up+B.
When you hold a direction, you get a menu with 5 items (1-5, from bottom to top). If you want the first item, press C. If you want the last item, press A. For any other item, press B then roll your thumb down (B+C = 2) or up (B+A = 4), or simply release it again (3). At least for me, doing it this way made it pretty intuitive and quick. No third finger needed.
For other characters, I was thinking of using button A (without a direction) to cycle the tree root. So you press A to type special characters, press A again for frequently used words, and again to go back to the alphanumeric mode. Or something like that. It’s flexible, the trees can be specific for the input you need. For programming, instead of typing letter-by-letter, you’d type entire keywords at once and autocomplete would help with things like parenthesis and brackets.
For the terminal emulator in my loader, the first tree would have commands (cd, mkdir, rm, mv, etc) instead of letters, and it would automatically change tree depending on the arguments the command needs. So you’d select mkdir and then type the directory name letter-by-letter.
1 Like
Can’t wait for that terminal  It has to have tab-completion and command history, that’s what saves most time.
It has to have tab-completion and command history, that’s what saves most time.
1 Like
Today I’ve added selection and themes:
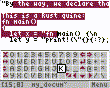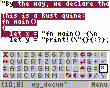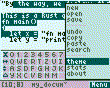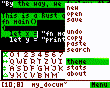
2 Likes
Still working on this! I’ve added runtime switchable layouts for the keyboard, copy/paste, simple one line popup text handler (for short answers, like a file name query… there will be a single function for this), searching and tabs that behave exactly like you’re used to (not just multiple spaces, but real tab stops).
Things I think I’ll drop: line numbers (you can see the line number on the info bar at the bottom) and search+replace (too much GUI). People will be able to add these in specialized forks (e.g. a specialized programming editor could add line numbers as well as syntax highlight and other things.)
The name could be PokiPad? Or pedit (like gedit)? It means something in Finnish
Still thinking about the undo – I have decided there will only be one undo, but still it’s difficult, because I’d like some actions to be grouped together – for example a continuous deleting with backspace will be one undoable operation, no matter how many characters you delete. The same goes for continuous typing. Also if you select a text and type a character, the selection gets deleted and replaced by the character – these two actions will be grouped as well.
Saving/loading files will probably be the painful part, because the emulator support filesystem only partly and I’ll have to handle special situations like opening a file that’s too big (load only part of it as a new file) or opening a non-ASCII document (show a warning and replace unsupported/unknown symbols by some equivalent characters… but also will have to handle variable width encoding such as the UTF).
EDIT:
Hmm let’s rather use ISO 8859-1 encoding – an extension of ASCII universal for most languages.
That’s a plural form of “peti”, which is means a bed. So that is beds in English.
1 Like
I gave up on working on this. :P
There’s no sense in three of us attempting the same thing, and I’ve got other things I could be working on.
Except Finnish, French, German, Welsh, Irish, Dutch, Danish, Estonian and Catalan.
You won’t be able to program FALSE in it, because there’s no ẞ.
Windows-1252 fixes some of these issues, and aparently HTML5 mandates that ISO 8859-1 documents be interpreted as WIndows-1252.
There’s also ISO/IEC 8859-14, which fixes a lot of the Irish problems, but sacrifices the ¥ and ¢ signs (among others).
Neither of those feature a ẞ though…
1 Like
Oh no  Czech probably either, I can’t see “ř” in there.
Czech probably either, I can’t see “ř” in there.
Then there is 8859-15 which adds some more characters, but mostly only euros? I’ll have to go study encodings for a while now.
Anyway, as I see it, the editor will internally only support ASCII, because:
- Pokitto fonts only go up to 127. I’d have to make my own.
- Keyboard doesn’t have special chars anyway.
- This is really a basic 4fun program for basic plaintext, nothing fancy.
So I’ll just suppose some common encoding and convert that to ASCII. Would be great to be able to detect UTF8 and convert it so that it doesn’t completely break, but that’s it. Again, let’s leave advanced encoding stuff up to forks.
EDIT:
Seems like 8859-15 addressed the missing language characters, so this could be the one we’ll suppose…
1 Like
I think the easiest solution would be to use UTF16, but only support a specific subset of it.
UTF16 covers the “basic multilingual plane” (plane 0, 0x0000 to 0xFFFF) of Unicode.
Which looks like this:

So basically, a large chunk of that is the more complex CJK (Chinese, Japanese Korean) characters, (i.e. kanji, hanzi, hanja, hangul) which are actually pictograms rather than syllabaries.
(To put things into context, there are about 3,000-6,000+ kanji in everyday use.)
You could cut out all that (possibly leaving the syllabaries to avoid cutting the languages out altogether),
plus the symbols (e.g. the maths stuff), plus the ‘private use’ areas and you’d probably only have a small chunk left to worry about.
There’s probably some others you could cut out too.
Still doesn’t have ẞ.
German must be a very disliked language to have ẞ cut out of so many encodings.
How else am I suppsoed to say “Gehe sie erste straẞe rechts.” or “Ich mag der straẞenbahn”? :P
1 Like
Hmmm you’re totally right, I should suppose UTF. Though I think UTF8 will be the one, because
UTF-8 has an advantage in the case where ASCII characters represent the majority of characters in a block of text, because UTF-8 encodes all characters into 8 bits (like ASCII). It is also advantageous in that a UTF-8 file containing only ASCII characters has the same encoding as an ASCII file.
– SO
Just use B for now, we’ll make a German plugin later if there is demand
EDIT:
A UTF-8 processor which erroneously receives an extended ASCII file as input can “fall back” or replace 8-bit bytes using the appropriate code-point in the Unicode Latin-1 Supplement block, when the 8-bit byte appears outside a valid multi-byte sequence.
Very nice.
The downside to UTF8 is that you have to do a lot more extra processing to decode the variable-length encoding.
With UTF16 you don’t have to do any bit shifting,
but with UTF8 there’s a lot of shifting and masking involved.
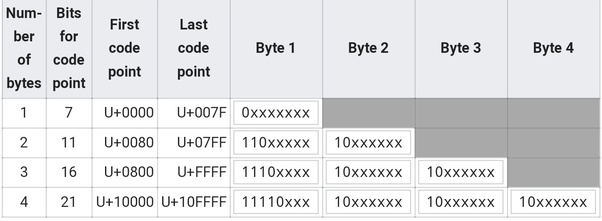
In contrast UTF16 covers the entire basic multilingual plane in a single unit (2 bytes), and everything else using two units in the form of ‘surrogate pairs’, but the basic multilingual plane covers almost all ‘modern languages’ so you won’t really need to worry about surrogate pairs beyond recognising and ignoring them.
“when the 8-bit byte appears outside a valid multi-byte sequence.” being the key phrase there.
There are cases where it fails, and there are different variants of extended ASCII, so knowing what the intended variant was is practically impossible.
in German, you can replace the ‘Eszett’ by ss… So that beta symbol is not really necessary, I think. https://en.wikipedia.org/wiki/ß
1 Like
Given what this section says, I wouldn’t want to assume that without actually asking a native.
Thus it helps to distinguish words like Buße (‘penance, fine’: long vowel) and Busse (‘buses’: short vowel)
The same rules apply at the end of a word or syllable, but are complicated by the fact that single s is also pronounced /s/ in those positions. Thus, words like groß (‘large’) require ß, while others, like Gras (‘grass’) use a single s. The correct spelling is not predictable out of context (in Standard German pronunciation), but is usually made clear by related forms, e.g., Größe (‘size’) and grasen (‘to graze’), where the medial consonants are pronounced [s] and [z] respectively.
(Plus, you still wouldn’t be able to write in FALSE.)
@Pharap this is what we learned at school… And German is 1 of the 3 official languages here… However I am not a native speaker.
We also learned German at school and from what I remember we were taught to use ‘ß’, not to treat it as interchangable with ‘ss’.
(Though German isn’t an official language here, and it wouldn’t be the first time the curriculum screwed up…
and to be honest I wasn’t paying full attention because I was learning it against my will, but that’s a story for another day).
Either way I’d rather check with a native.
Natives tend to understand the nuances of a language better than any textbook.
For example, most English textbooks would tell you “pass me them spanners” isn’t correct English, but I know for a fact that up north and in certain southern counties (e.g. Somerset) that’s a common colloquialism.
But ultimately I’m not the one writing it, all I can do is put forward arguments/reasons.
If what I say is dismissed, so be it. ¯\_(ツ)_/¯
1 Like